Learn how SSRF flaws arise, why three common attack paths are so challenging to mitigate and how Tenable.io Web Application Scanning can help.
Modern web applications are designed with different services — like internal and external application programming interfaces (APIs), microservices and databases — that communicate and share data with each other. These web applications provide end users with convenient features, such as loading external content.
An unfortunate side effect of this functionality is the potential to open the doors for attackers to exploit server-side request forgery (SSRF) vulnerabilities, a complex type of web application security vulnerability with potentially significant impact. SSRF flaws have become so commonplace that they’re now part of the Open Web Application Security Project (OWASP) TOP 10 for 2021.
What is a server-side request forgery?
SSRF is a vulnerability that allows an attacker to abuse an application's functionality by providing an arbitrary URL without filtering or validation in order to make a new request to a third-party service or resource, normally accessible only from the internal network. An SSRF can be used by an attacker to access internal services that may be sensitive or to retrieve resources such as configuration files containing credentials and other secrets.
As a request is made from a component that would normally interact with an internal network service, it may be allowed to pass through firewalls, so an SSRF can introduce significant risk to sensitive business systems.
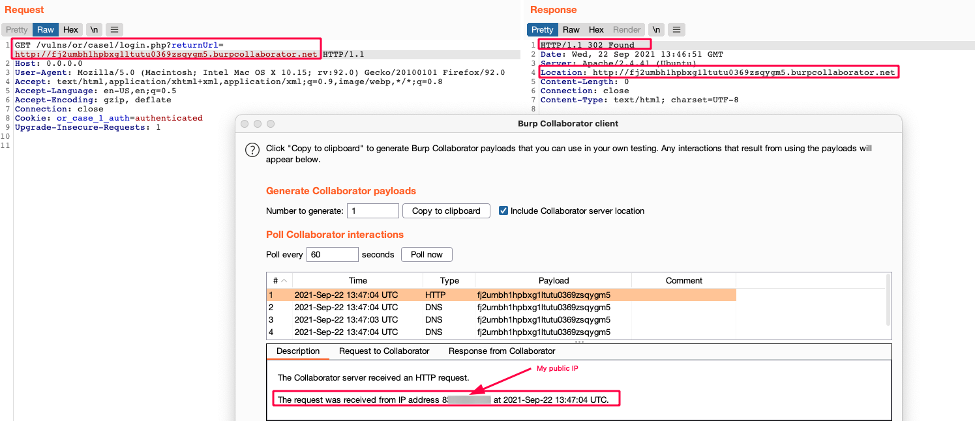
Before getting to the heart of the matter on the exploitation and the potential risks of this type of vulnerability, it is necessary to understand some basic concepts. In my experience, security practitioners often confuse SSRF with an open redirect vulnerability, which are two distinct vulnerabilities with two completely different impacts.
Consider the following example:

If the GET “returnUrl” parameter is supplied by the user, then the website will redirect to the provided value. So in this case, when the URL “http://domain.tld/?returnUrl=https://evil.org“ is supplied by the attacker, the browser makes an HTTP request and redirects the user to “https://evil[.]org”.
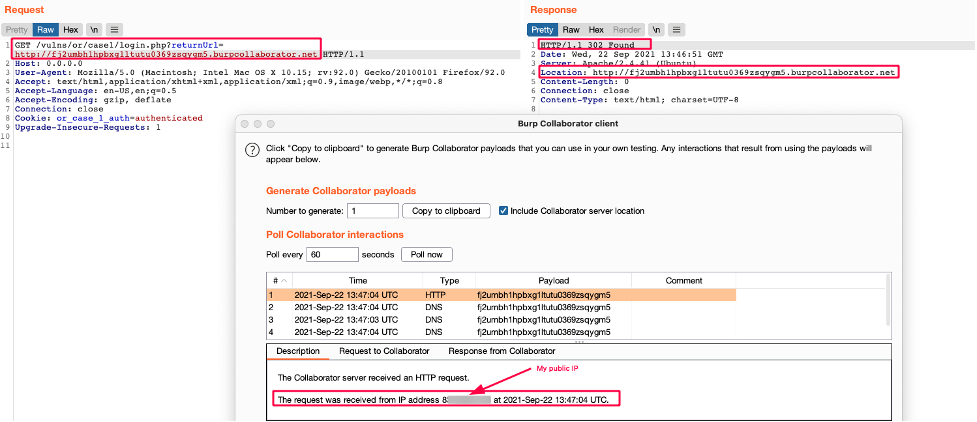
In the example above, the redirection is carried out on the client-side and not by the server itself. It is therefore impossible to reach an internal resource, because it's like trying to reach an internal company server directly from your browser, which is technically impossible if it does not have a public IP address.
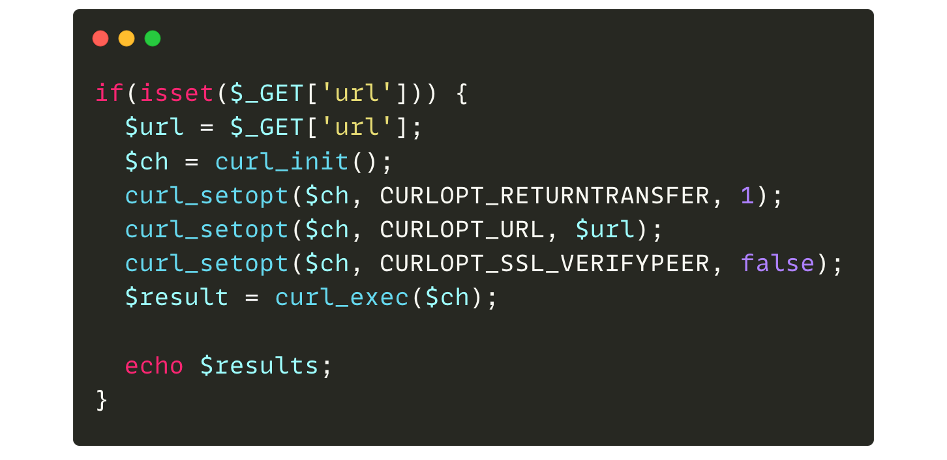
Now, let’s take the following example:
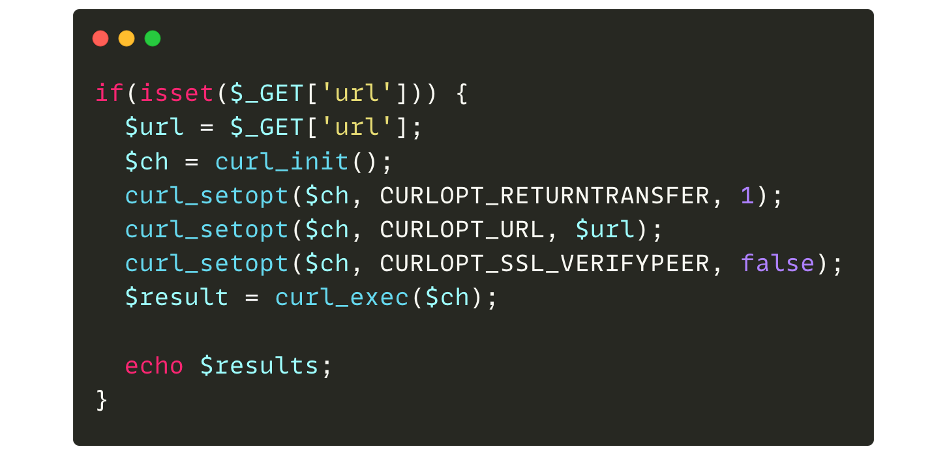
If the GET “url” parameter is supplied by an attacker, a curl request is made and the result is displayed. If we therefore pass an arbitrary URL, the code will take care of retrieving the content of the page and displaying it:
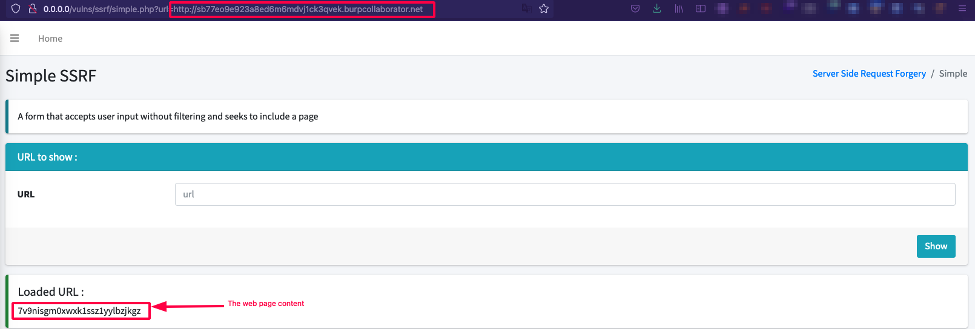
Just like the previous case, an HTTP request is made to the resource. However, in this case, the request comes from the server itself (server-side request) and not from the browser (client-side request).
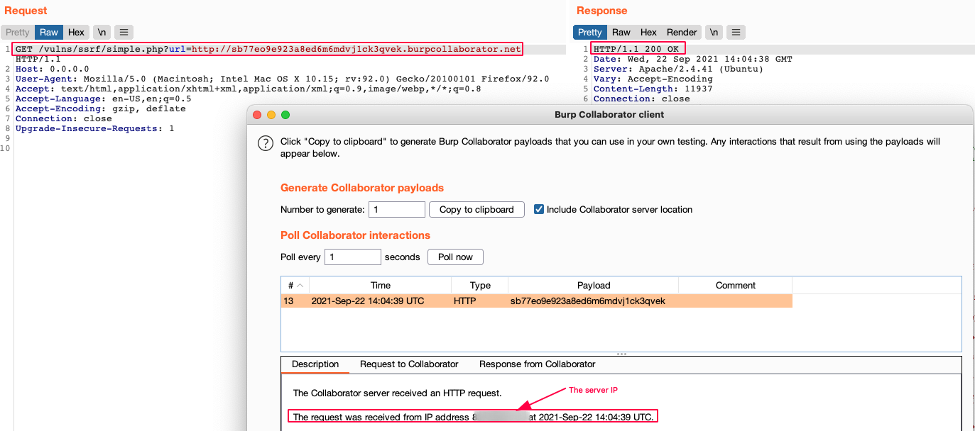
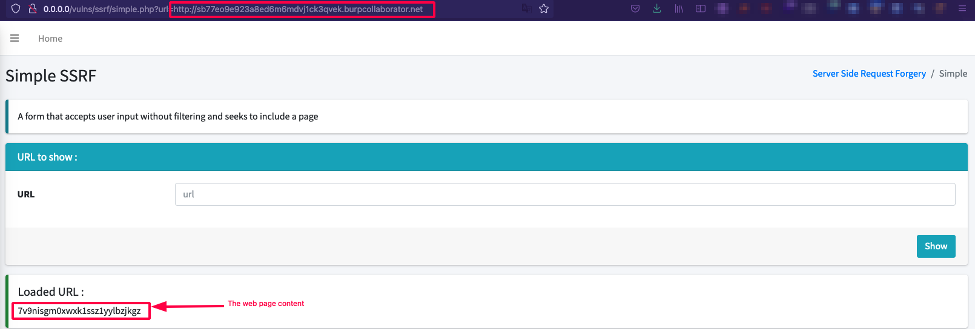
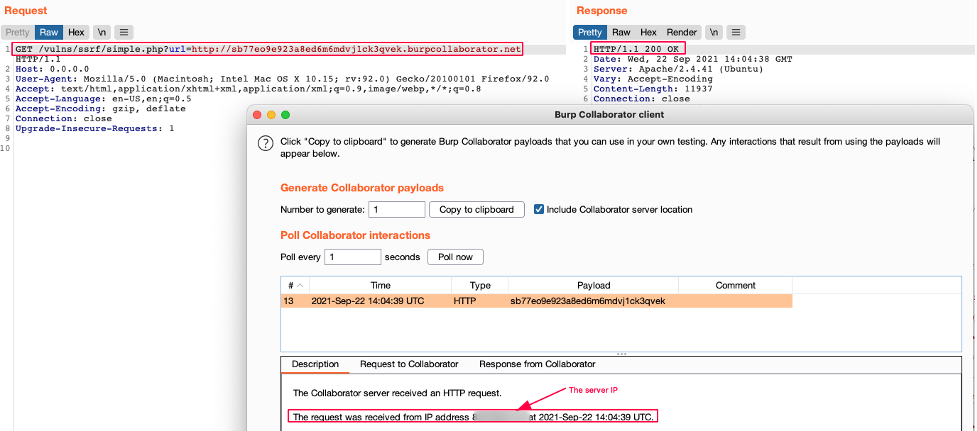
This specific case does not demonstrate an SSRF vulnerability because it could be quite normal and expected that the web application can fetch content from an external resource, e.g. adding an avatar to a profile. In the avatar example, a web application could enable the user to select an image from their hard drive or from a remote URL. Popular services like Twitter offer a preview of a URL within a tweet, and this preview makes a legitimate HTTP request to a service level application.
Modern web application architectures often include many microservices and APIs (Rest, GraphQL, etc.) and these services often need to communicate with each other. For example, a course centralization service could ask a user for the URL of a course in JSON format in order to integrate it into the platform. The application would therefore make a legitimate HTTP request to the ressource. However, in the event that no filtering or validation is performed, the user could pass an arbitrary URL in order to retrieve a private ressource.
In this example, the SSRF vulnerability occurs when a web application fetches an unauthorized ressource on a URL outside the authorized scope, such as the internal network.
Three common attack paths for SSRF exploits
SSRF provides attackers with multiple exploitation options. Three examples of common attack paths are:
- Read arbitrary files on a server with the “file://” wrapper
- Interact with other services with the “http://” or ”gopher://” wrappers and possibly achieve Remote Code Execution (RCE)
- Blind exploitation
Read arbitrary files on a server with the “file://” wrapper:
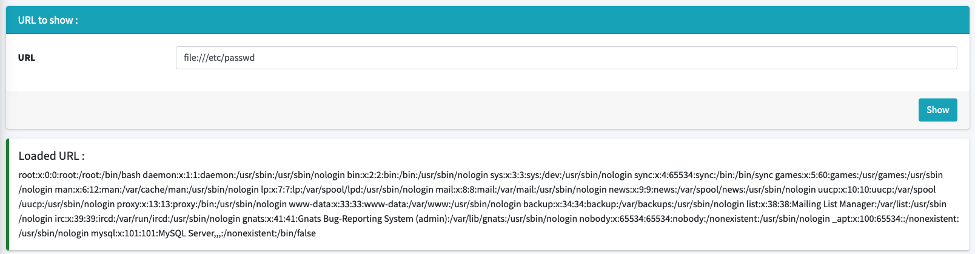
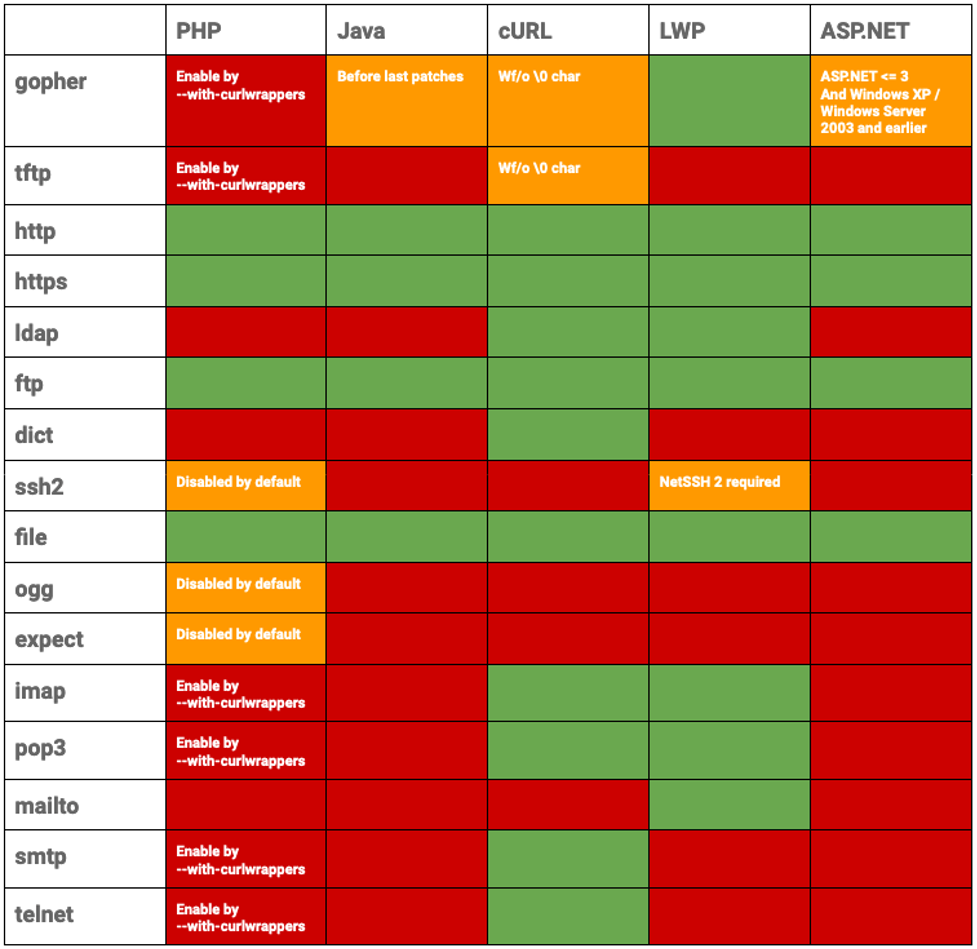
Rather than using “http://”, we can force a web application to use the “file://” wrapper which is a URI (uniform resource identifier) scheme typically used to find files on your own computer. So using “file:///etc/passwd” in the address/URL bar or via a curl command ("curl ‘file:///etc/passwd’") in the terminal will display your own “passwd” file.
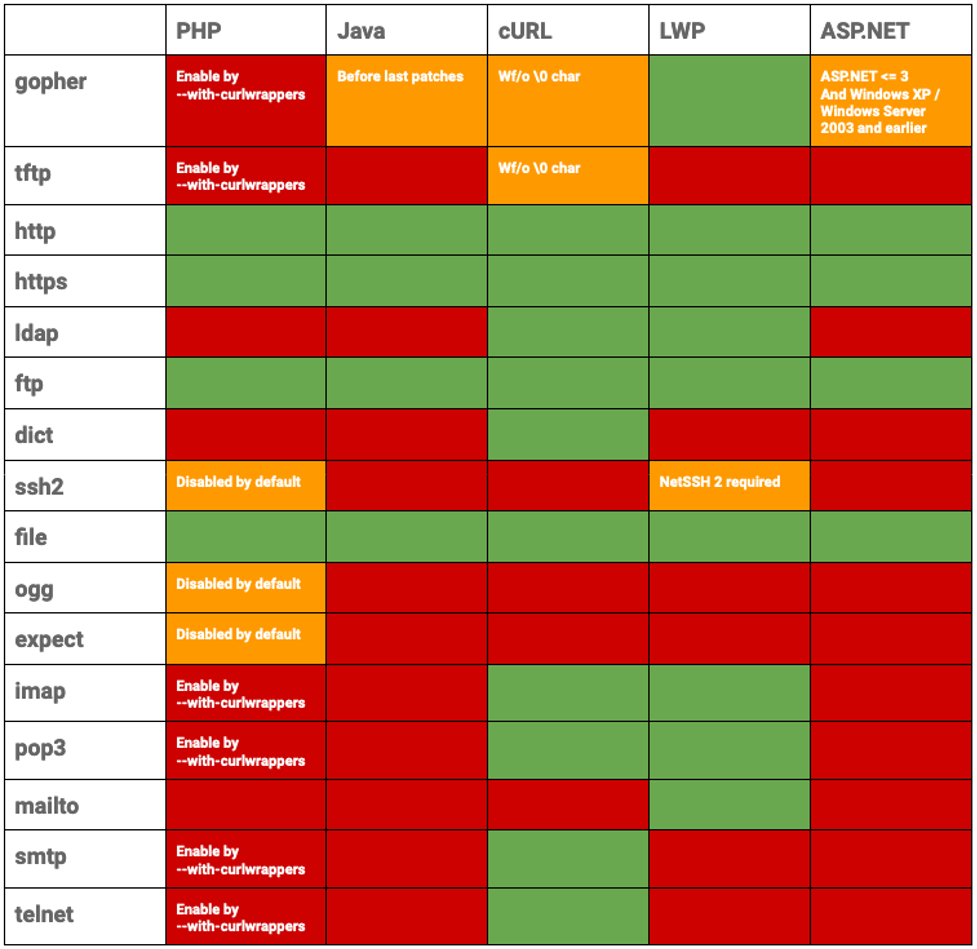
While there are a variety of wrappers that can be used for different use cases, the “file://” wrapper is often enabled by default, making it an attractive target for SSRF attacks. The following table highlights which wrappers enable the file wrapper by default:
To illustrate the previous case, on a vulnerable application, we can use the file wrapper to fetch the passwd file by using "file:///etc/passwd" instead of the expected URL:
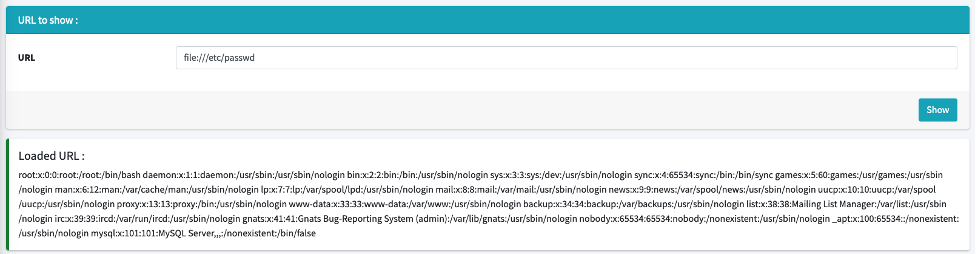
One possible solution to this flaw would be simply to prohibit the use of another wrapper or to perform tighter control on the user supplied input of a URL. However, because of the massive adoption of cloud services and the use of the “http://” wrapper, this opens the door to new possibilities.
Interact with other services
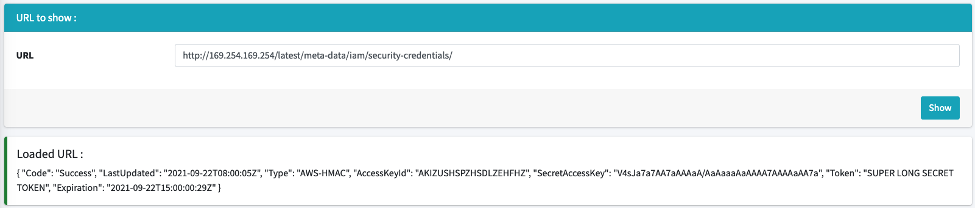
When using a cloud provider such as Amazon Web Services (AWS), it is possible to access server metadata, which is data about the AWS instance that can be used to configure or manage the running instance, more information here) via a URL that is normally only accessible from the server itself.
Example URLs from some of the most popular cloud providers are:
- http://169.254.169.254 for AWS, Google Cloud Platform (GCP), DigitalOcean and Azure
- Link local address (normally used when an interface configured as a dynamic host configuration protocol (DHCP) client does not get a response from a DHCP server)
- http://192.0.0.192 for Oracle Cloud Infrastructure
- Bogon (non-reachable private IPs) IP address reserved for special use, such as for local or private networks, and should not appear on the public internet
- http://100.100.100.200 for Alibaba Cloud
- Bogon IP address reserved for special use, such as for local or private networks, and should not appear on the public internet
Despite the use of non-reachable private IPs, in the case of a SSRF attack, the server itself makes the request which grants authorized access to these resources, allowing an attacker to read the contents of the metadata.
As an example, cloud services like AWS provide endpoints that return metadata containing some sensitive data and secrets. This information is tied to a special token associated with the AWS account. When the metadata is retrieved, this information can then be used with the AWS Command Line Interface to access resources associated with the AWS account according to the privileges defined by the retrieved token.
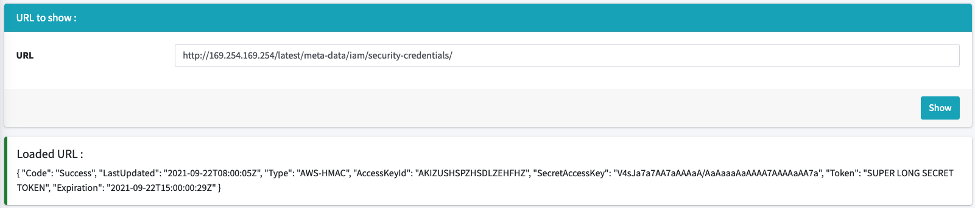
To guard against this, some cloud providers, like DigitalOcean, will simply not show sensitive information, while in the case of AWS or GCP, it is necessary to include a specific header with the request. Although this mitigates the vulnerability, it is not always enough.
There is always the possibility of accessing sensitive information in certain cases, especially if a cloud-init file is used to install the server and the server contains secrets. Instead of searching the metadata, it is possible to search directly for publicly accessible sensitive files.
One example is a challenge from the 2021 Tenable Capture The Flag competition. The objective of the ‘Hacker toolz’ challenge was to retrieve the metadata of a protected AWS server and require a specific HTTP header to be queried.
One web page allowed a screenshot of a supplied website to be displayed. The screenshot was taken by a browser which accessed the page, took the screenshot and displayed it to the user. With a custom site using custom JavaScript, it’s possible to force the browser to execute an HTTP request to the AWS metadata with the necessary elements to then be returned to the attacker.
This case is possible because the browser was installed on the same server, which meant it was allowed to access that server's metadata. This is a common scenario today, as explained by Ben Sadeghipour, manager, hacker operations at HackerOne and Chris Holt, senior bug bounty operations lead at Verizon Media, during their presentation Owning the cloud through SSRF and PDF Generators at AppSec California 2020.
We could then say that applying a blocklist would be a good mitigation strategy. However, the use of the blocklist is never recommended because it is too difficult to anticipate and cover all possible cases.
If the URL http://169.254.169.254 is blocked, the following cases (not exhaustive) remain possible:
- Use a DNS record that points to 169.254.169.254
- Use HTTP redirect
- In the case of a browser for example, it could follow the redirection and therefore bypass the first filter
- Alternate IP encoding with annotations other than standard IPv4
- Ex : http://2852039166/ => Dotless decimal
The examples presented so far are exploitable in cases where the content returned is displayed to the user, but it is not always possible to have the returned content of our request displayed. We will now see that even through blind scenarios, it is still possible to exploit the vulnerability with a critical impact.
Blind exploitation
In the case of limited output, it is not always possible to retrieve file contents or a complete web page. It is, however, possible to query internal services and possibly execute arbitrary commands. Some options include querying the following:
- Services on another port
- Other servers accessible on the network
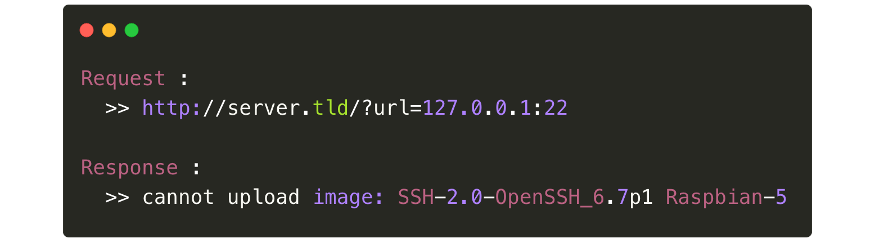
One trick when testing file upload functionality is to attempt to request “127.0.0.1:22” and the server could respond with the server's OpenSSH banner.
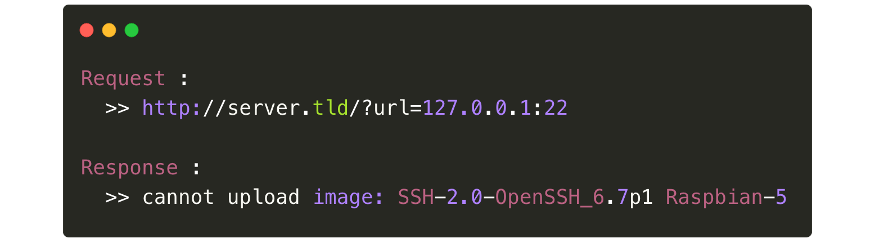
This example can also work when the application responds with different status code.
- HTTP Response 200 OK => port open
- HTTP Response 500 Internal Server Error => port closed
In the case of blind operation (no output received), it may be possible to enter internal IPs looking for reachable servers or try to contact the server itself on different ports.
By analyzing the response time of requests, it is possible to determine whether a service is accessible or not. During a blind scan, it is first necessary to understand how the network works because a short or long response time does not necessarily indicate an open or closed port:
- A long response time can indicate that the request is not routed or blocked at a moment. Additionally, network latency from other traffic could result in a long response time.
- A short response time could indicate a blocked request.
However, it can take time to explore the network for an interesting service. For instance, identifying a JBoss server will allow for a query chain that can be used to deploy a malicious package.

Source : https://blog.safebuff.com/2016/07/03/SSRF-Tips/
In some cases it is also possible to achieve RCE by exploiting the vulnerability of another service and allow an attacker to gain a foothold in the internal network.
For example, one could exploit CVE-2020-35476, an RCE vulnerability in the OpenTSDB service, which is normally only accessible internally.

Source : https://github.com/OpenTSDB/opentsdb/issues/2051
This proof-of-concept creates a file on the system, which could allow an attacker to establish a reverse shell.
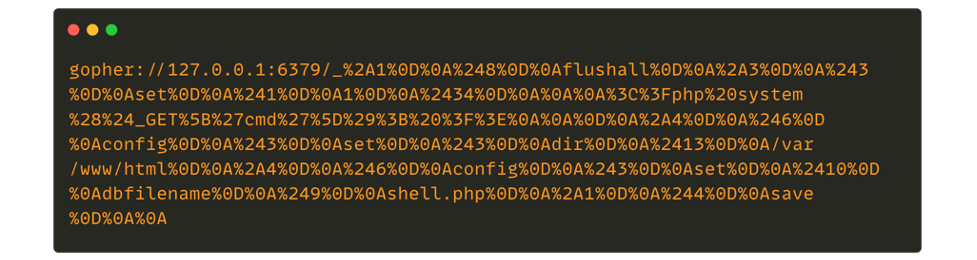
The final attack scenario we will cover for this blog post is the use of the “gopher://” wrapper, which is particularly interesting in the case of a blind SSRF. To keep it simple, “gopher://” is a distributed document delivery service, an alternative to the internet that we know today. This specific wrapper, which is not activated by default, allows the creation of very specific URLs in order to transmit instructions to a service. Thus, with this wrapper it is possible to:
- Interact with a MySQL/Redis/Zabbix server
- Sends emails through SMTP
However, the use of this wrapper also requires knowing the service that we are going to query. Here are a few example scenarios:
- In the case of MySQL, an attacker would need to know the identifiers of the database before creating a forged query.
For Redis, the URL sent will also have to respect a specific format which is RESP Arrays. The following is an example of a payload gopher to interact with a Redis database:
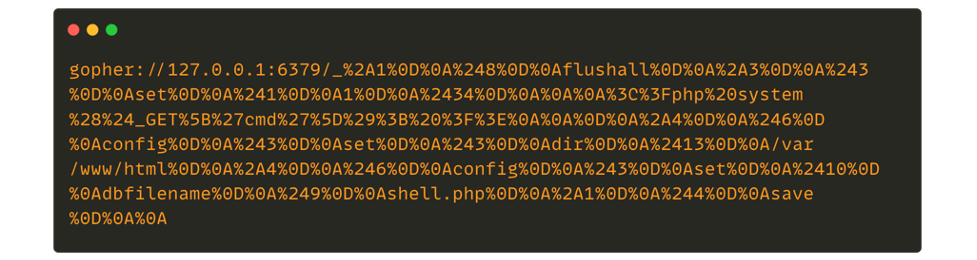
In some cases, it is also necessary to know the target operating system to carry out the attack.
In the case of Redis, it is possible to obtain a reverse shell, though this only works on CentOS hosts since the cron file is modified. After the modification by Redis, the cron file will have its permissions changed from “0600” to “0644” which means that it cannot be executed.
In addition, using this technique injects unexpected characters into the file and even when changing the permissions of the cron file, this attack does not seem to run successfully on Ubuntu and Debian due to unexpected characters.
If the target application is running as root, as is the case with Ubuntu and Debian, then an attacker may be able to to inject their SSH key and access the server via SSH.
Prevention and mitigation strategies
There are multiple best practices available to protect web applications and users in order to avoid vulnerabilities like SSRF:
- Sanitize user-supplied inputs: If the web application can only send a request to identified and trusted applications, one possible countermeasure is to apply the allowlist approach.
In the event that the applications in question are not known :
- Disable browser-level redirects to avoid filter bypass
- Input validation techniques can be added to ensure that the input string respects the expected format.
- If possible, verify if the data received has the valid and expected format. When possible, validation should be done through available libraries, because regexes for complex formats are difficult to maintain and are error-prone.
- Double checkthe destination: In the case of an IP address, verify that it corresponds to a public IP. In the case of a domain name, ensure that it is resolvable at DNS level.
- Enforce URI Schemas: Be restrictive by allowing only URI schema that you need, such as “http://” or “https://”
- Apply strong configuration for cloud services: AWS and other cloud vendors provide solutions/mitigations by applying more robust configuration to mitigate SSRF vulnerabilities There are hardening solutions for each provider (e.g,: prevent containers to accessing AWS metadata)
- In general, it remains necessary to have a robust policy on the management of your identity and access management (IAM) policy and limit the permissions of generated tokens, which are used to communicate with the different services from the API to the necessary needs.
- Even with Instance Metadata Service Version 2 (IMDSv2) on AWS, the use of a headless web engine (like Chromium) opens the door to workarounds, so we must identify the possible attack vectors and possible solutions.
- For PDF generation, filter the user inputs to not allow the inclusion of HTML tags.
Use Tenable.io Web App Scanning to detect server-side request forgery flaws
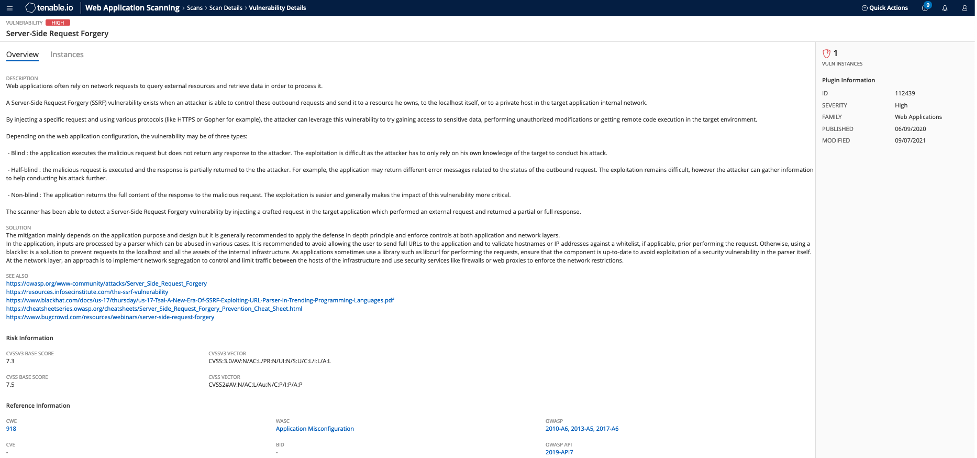
Tenable.io Web App Scanning helps identify SSRF vulnerabilities through multiple features, including the following dedicated plugin:
- Plugin 112439 can detect generic SSRF issues and helps identify commonly associated SSRF vulnerabilities, such as CVE-2014-4210, CVE-2020-7616, CVE-2020-29444, and CVE-2021-21311.
Get more information